

TL;DR
A website crawler, also known as a spider or spiderbot, is an internet bot that systematically browses the World Wide Web. Operated by search engines like Google, its primary purpose is to discover and download content from web pages, follow links to find new pages, and provide this data to the search engine. This information is then used to create a searchable index, allowing users to find relevant results for their queries. Without crawlers, search engines would be unable to find and rank your website's content.
What Is a Web Crawler and How Does It Work?
A website crawler is an automated software program that search engines use to navigate the internet in a methodical, automated manner. You may also hear it referred to as a 'spider,' 'spiderbot,' or simply a 'bot.' These crawlers are the foundational technology that powers search engines like Google and Bing. Their core function is to visit web pages, read their content, and follow the links on those pages to discover new content, continuously expanding the search engine's map of the internet.
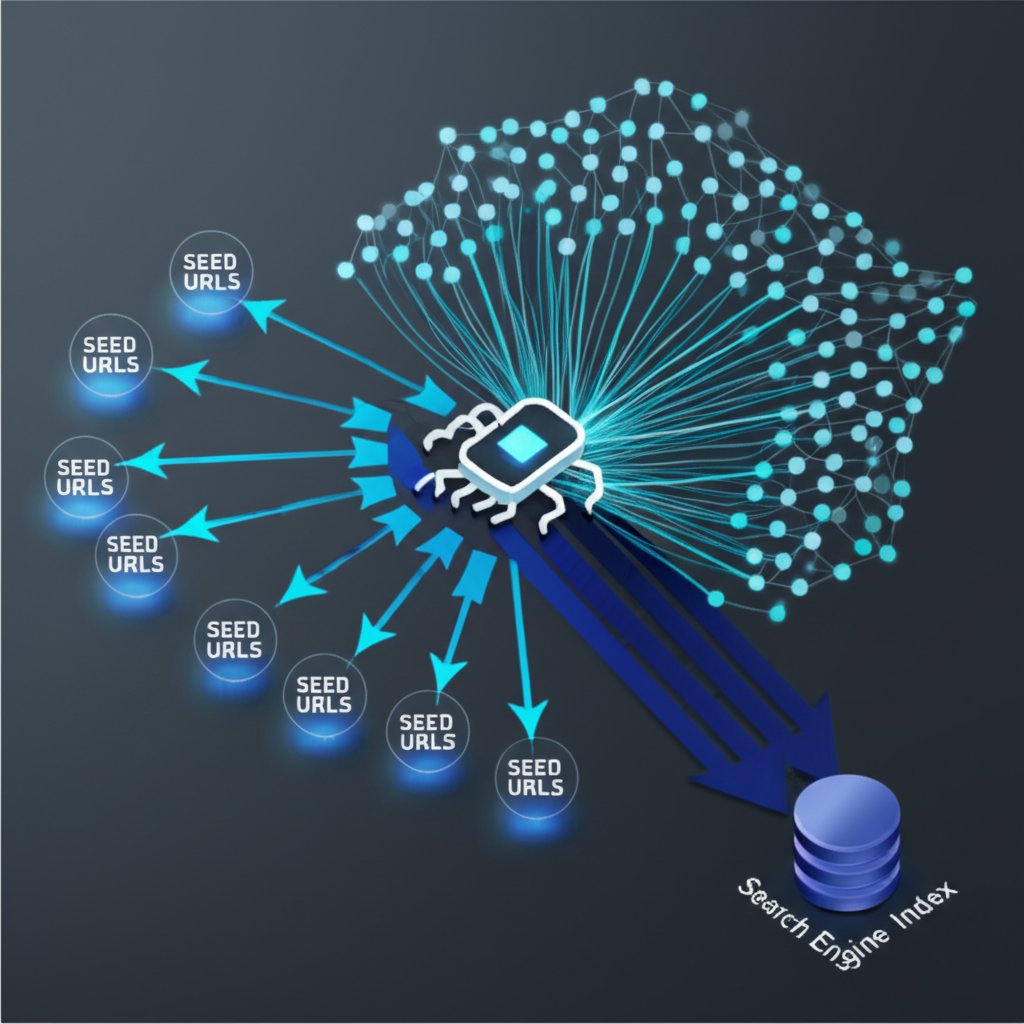
The process begins with a list of known URLs, called 'seed URLs.' The crawler visits these pages first. As it analyzes a page, it identifies all the hyperlinks pointing to other pages and adds these new, undiscovered URLs to a list called the 'crawl frontier.' The crawler then systematically works through this frontier, visiting new pages and repeating the process. This recursive method allows crawlers to discover a vast number of interconnected pages across the web. Well-known examples of these bots include Google's Googlebot and Microsoft's Bingbot.
As the crawler collects data from each page—including text, images, metadata, and the links it contains—it sends this information back to the search engine's servers. The search engine then processes and organizes this data into a massive database known as a search index. Think of this index as a library's card catalog for the entire internet. When you perform a search, the engine doesn't scan the live internet; instead, it rapidly searches this pre-built index to deliver a list of the most relevant pages. This entire discovery and indexing process is what makes it possible for your website to appear in search results.
Web Crawling vs. Web Scraping: Understanding the Key Differences
While the terms 'web crawling' and 'web scraping' are sometimes used interchangeably, they describe fundamentally different activities with distinct purposes and methods. Web crawling is a broad, discovery-oriented process used by search engines to index the web. Its goal is to create a map of the internet so that content can be found and ranked. Crawlers are generally designed to be 'polite,' often respecting a website's rules outlined in a file called `robots.txt`.
Web scraping, on the other hand, is a targeted data extraction process. A scraper is a bot designed to pull specific pieces of information from a website, often without permission. For example, a scraper might be programmed to harvest all product prices from an e-commerce site, collect email addresses from online directories, or download articles from a news source. Unlike the broad exploration of a crawler, a scraper has a narrow, specific objective: data acquisition.
The distinction also extends to scope and legality. A search engine crawler like Googlebot aims to browse as much of the web as possible, continuously following links. A scraper typically focuses on a single site or a small set of pages to get the data it needs. Furthermore, while crawling is a legitimate and necessary function for the web's operation, scraping often operates in a gray area and can be malicious if it involves harvesting copyrighted content or personal data against a site's terms of service. Many scrapers intentionally ignore `robots.txt` rules and may disguise their identity to avoid being blocked.
| Aspect | Web Crawling | Web Scraping |
|---|---|---|
| Purpose | Broad discovery and indexing of web pages for search engines. | Targeted extraction of specific data (e.g., prices, contacts, content). |
| Scope | Vast; attempts to cover as much of the public web as possible. | Narrow; focused on specific websites or even specific parts of a page. |
| Method | Follows links recursively to discover new content. | Programmed to locate and pull predefined data elements from a page's code. |
| Permission | Generally respects `robots.txt` file directives. | Often ignores `robots.txt` and terms of service; can be unauthorized. |
Optimizing Your Website for Crawlers (SEO Best Practices)
Ensuring that search engine crawlers can efficiently find, access, and understand your website's content is the cornerstone of technical search engine optimization (SEO). If a crawler can't properly access your pages, they won't be indexed, and as a result, they won't rank in search results. Optimizing for crawlers, often called 'crawlability,' involves several key practices that make your site easy for bots like Googlebot to navigate.
One of the most direct ways to guide crawlers is by using a `robots.txt` file. This simple text file, placed in your site's root directory, tells crawlers which pages or sections of your site they should or should not access. For example, you can use it to block crawlers from accessing private admin pages or duplicate content. Additionally, submitting an XML sitemap via a tool like Google Search Console provides crawlers with a direct roadmap to all the important pages you want them to index, which is especially useful for large or new websites.
A well-organized site structure with a logical internal linking strategy is also critical. Crawlers discover pages by following links, so ensuring your most important pages are linked from your homepage and other prominent pages helps them be found quickly. Furthermore, site performance plays a significant role. Crawlers operate on a 'crawl budget'—a finite amount of resources they will dedicate to your site. Slow-loading pages and server errors waste this budget, potentially leaving important pages uncrawled. Fixing broken links (404 errors) and minimizing redirect chains also helps preserve your crawl budget and provides a better experience for both bots and users.
Ultimately, high-quality, well-structured content is fundamental for both users and crawlers. Creating valuable articles that are easy for bots to parse can be a time-consuming process. For marketers looking to scale their content creation while maintaining SEO standards, AI-powered tools can be a significant asset. For instance, platforms like BlogSpark can help generate engaging, SEO-optimized articles quickly, ensuring that the content produced is structured in a way that is easily crawlable and indexable by search engines.
Here are some actionable steps to optimize your website for crawlers:
- Submit Your XML Sitemap: Provide a direct map of your important URLs to search engines through tools like Google Search Console.
- Use `robots.txt` Intelligently: Guide crawlers away from non-essential or duplicate pages to conserve your crawl budget.
- Strengthen Internal Linking: Ensure your key pages are linked logically from other parts of your site so crawlers can discover them easily.
- Improve Page Load Speed: A faster site allows crawlers to visit more pages within their allocated crawl budget. Use Google's PageSpeed Insights to identify areas for improvement.
- Fix Broken Links and Redirects: Eliminate 404 errors and long redirect chains that confuse crawlers and waste their time.
- Check for Crawl Errors: Regularly monitor reports in Google Search Console to identify and fix any issues that prevent crawlers from accessing your content.

Types of Web Crawlers and Common Tools
Web crawlers are not a monolithic group; they can be categorized based on their purpose, architecture, and the entity that operates them. The most well-known type is the search engine crawler, such as Googlebot or Bingbot. These are large-scale, general-purpose bots designed to index as much of the public web as possible to power search results. Their goal is comprehensive discovery and indexing.
A second major category is the commercial SEO crawler, often referred to as an SEO spider. These are specialized software tools designed for website owners, marketers, and SEO professionals to audit their own websites. Unlike search engine crawlers that roam the entire internet, these tools are focused on a single domain at a time. They help identify technical issues like broken links, redirect chains, duplicate content, and missing metadata. One of the most popular tools in this category is the Screaming Frog SEO Spider, a desktop application that provides detailed site audits.
Finally, there are custom crawlers and scrapers. These are often built using open-source frameworks like Scrapy or Apache Nutch for highly specific tasks. A business might develop a custom crawler to monitor competitors' websites, while a researcher could use one to gather data for an academic study. These crawlers can be highly focused, seeking only pages that match certain criteria (a 'focused crawler') or designed for large-scale data extraction. The line between these custom crawlers and web scrapers can be thin, as their function is often data acquisition rather than general indexing.
Here are some common web crawler tools available today:
- Screaming Frog SEO Spider: A powerful desktop website crawler used by SEO professionals for in-depth technical site audits.
- Sitechecker: An online tool that crawls websites to find broken links, indexing issues, and other technical SEO problems.
- Apache Nutch: A highly scalable and open-source web crawler framework that can be customized for large-scale crawling projects.
- Scrapy: An open-source and collaborative framework for extracting the data you need from websites, often used for web scraping.
Frequently Asked Questions About Website Crawlers
1. What does it mean when a website is crawled?
When a website is crawled, it means that a search engine bot, like Googlebot, has visited the site to discover and analyze its content. The crawler moves through the site by following links from one page to another, collecting information about each page it finds. This data is then sent back to the search engine to be processed and added to its index. Crawling is the essential first step before a website can be indexed and subsequently appear in search results for relevant queries.


